In this experiment we compare the lexical density of informative writing versus fiction.
To simplify matters, we chose to look only at Wikipedia articles and short stories.
The reason for this choice is that there are tools available which allow us to sample randomly
from large bodies of literature representative of different styles of writing.
Using Wikipedia's random article feature,
we pasted a random sample of 30 consecutive summaries of Wikipedia articles
(the text before the contents section with citation marks removed)
which were large enough to warrant having a "contents" section.
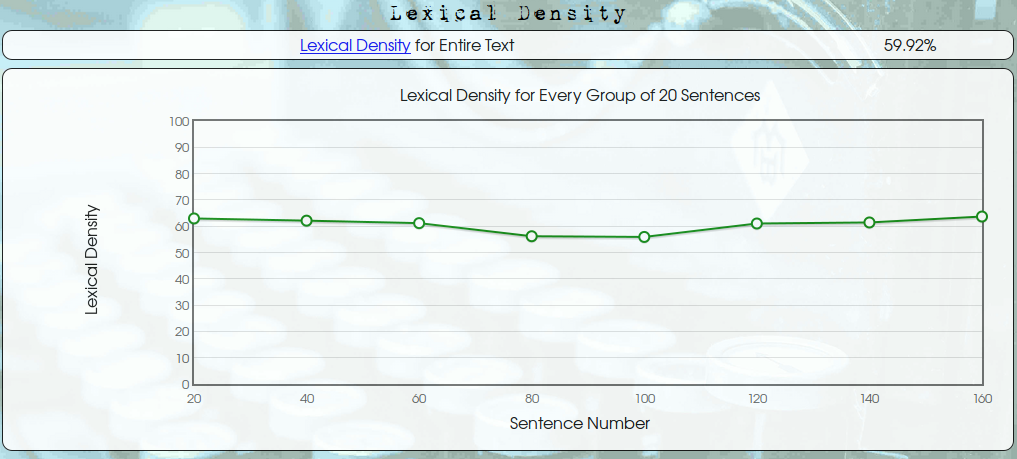
This yielded an average
lexical density of 59.92% as estimated by this website.
The results are shown below.
Next, we pasted a random sample of 30 consecutive first paragraphs of random short stories from the short story website
using their random story feature.
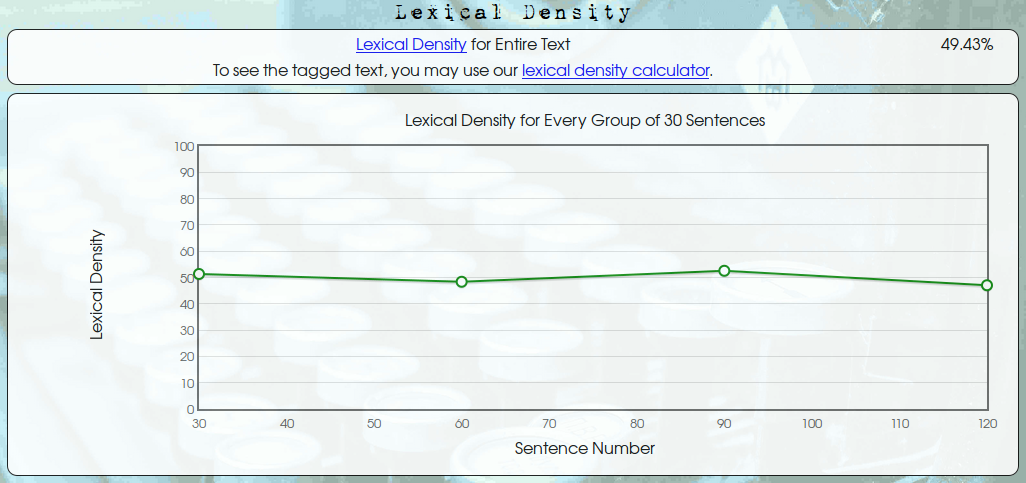
This yielded an average lexical density of 49.43% as estimated by this website.
The results are shown below.
Note: The reader will notice that informative writing tends to be quite lean in term of pronouns.
Also, the reader will notice that lexical density is simply the sum of the percentages
of nouns, adjectives, verbs, and adverbs as stated in the definition of
lexical density.
Finding the above analysis interesting, we decided it would be worth our while to analyze complete articles and
short stories.
We analyzed complete Wikipedia articles
and complete short stories from
a website (now defunct) which published short stories with a "random story feature."
Every Wikipedia article and every short story was again drawn randomly using both website's
respective random draw features.
The text analyzed for each Wikipedia article was all the text between the beginning of the article,
which was defined to be the first bold word (this excluded disambiguation and issues sections),
to the end of the article, which was defined to be where either the
"references," "external links," or "See also," sections began.
Analyzed text also included text from tables, and photo and figure captions.
Due to time constraints, citation marks and other bracketed notations were not removed.
The descriptive statistics of our sample are:
The histograms of both samples are shown below.
| Percent of Sample |
|
| |
Lexical Density Wikipedia Articles |
| Percent of Sample |
|
| |
Lexical Density Short Stories |
It is plainly visible from our histograms that there is quite a bit more variation among
Wikipedia articles than short stories on the website we visited. In line with this observation,
the reader will notice that the
standard deviation
for Wikipedia articles considerably higher than for short stories.
We pose the question to the reader: id this true in general for short stories?
Using the sample statistics from the above tables and the well-known
student's t-distribution
we can infer the following:
There is a 95% chance that the true average lexical density*
of Wikipedia articles lies between 55.29% and 57.63%.
There is a 95% chance that the true average lexical density*
of short stories at the short story website
lies between 48.93% and 50.59%.
*As measured by this website.
Lexical density, as measured by this website,
tends to be higher in informative writing than in fiction on the order of about 7%.
Our informal observations pointed to lexical densities around 60% for informative articles
such as Wikipedia articles and news articles and 50% for fiction.
A more complete analysis which considered whole articles and short stories, however,
revealed that that lexical densities for Wikipedia articles is likely somewhere between 55% and 58%.
An informal (non-random) sample of
New York Times
taken by this website yields similar results in the range of 58% for all the articles we looked at.
We encourage the reader to take this analysis further. Is this true
for news articles in general, or only New York Times articles?
Is there a difference according to political spectrum, or British, Australian, Canadian, or U.S.
news outlets?
Lastly, it is well-documented that lexical density tends to be lower in spoken English than in written English
(Johansson, Ure).
It would be very interesting to analyze interview transcripts or some other transcription of
spoken English to verify this observation.
Again, there is a wealth of tantalizing questions one could look at:
does lexical density vary between interviews with celebrities, politicians, musicians, or visual artists?
Maybe yes. Maybe no. That's for you, dear reader, to find out*.
*Update: We couldn't resist the temptation of trying this
experiment ourselves.
Johansson, V. (2008), Lexical diversity and lexical density in speech and writing: a developmental perspective, Working Papers 53, 61-79.
Ure, J. (1971), Lexical density and register differentiation. In G. Perren and J.L.M. Trim (eds), Applications of Linguistics, London: Cambridge University Press. 443-452.